Publications
publications by categories in reversed chronological order.
2026
- ECCV 2026
 SuperVoxelGPT: Adaptive and Ordered 3D Tokenization for Autoregressive Shape GenerationYuan Li, Congyi Zhang, Xifeng Gao, and Xiaohu GuoIn Computer Vision – ECCV 2026: 19th European Conference, Malmö, Sweden, Sep 2026
SuperVoxelGPT: Adaptive and Ordered 3D Tokenization for Autoregressive Shape GenerationYuan Li, Congyi Zhang, Xifeng Gao, and Xiaohu GuoIn Computer Vision – ECCV 2026: 19th European Conference, Malmö, Sweden, Sep 2026Autoregressive multimodal large language models (MLLMs) enable 3D generation but struggle to scale to high-resolution shapes due to inadequate 3D tokenizations. Compact set-based representations discard deterministic spatial ordering, leading to ambiguous sequence prediction, while uniform or octree-based voxel grids preserve ordering at the cost of severe redundancy and excessively long sequences. This structural trade-off limits stable and efficient autoregressive 3D generation. We present SuperVoxelGPT, a representation-first framework that resolves this tension through adaptive and deterministically ordered supervoxel tokenization. Given a prompt, we first predict a coarse geometric saliency distribution and construct a shape-adaptive supervoxel partition using saliency-guided centroidal Voronoi tessellation, allocating fine-grained cells to complex regions and larger cells to smooth regions. Conditioned on the text and ordered supervoxel layout, we introduce a SuperVoxelVAE and fine-tune a pretrained MLLM to autoregressively generate supervoxel tokens. Experiments on Trellis-500K show that SuperVoxelGPT reduces token sequence length to 12.8% of uniform voxel tokenization while achieving state-of-the-art generation quality and an average 10x speedup over prior methods.
- SIGGRAPH 2026
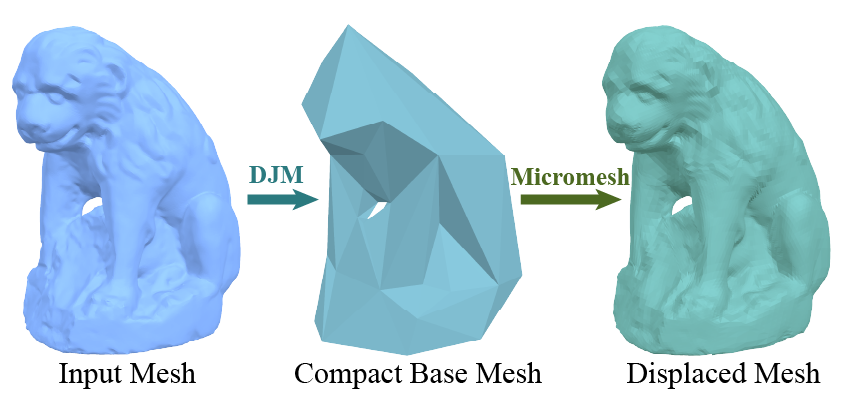 DJM: Compact Base Meshes for Displacement Mapping using Triangle JacobiansCongyi Zhang, Nicholas Vining, Yanhong Lin, Alireza Khatami, Ziyu Sun, Xiaohu Guo, Wenping Wang, and Alla ShefferIn ACM SIGGRAPH 2026 Conference Papers, Los Angeles, CA, USA, Jul 2026
DJM: Compact Base Meshes for Displacement Mapping using Triangle JacobiansCongyi Zhang, Nicholas Vining, Yanhong Lin, Alireza Khatami, Ziyu Sun, Xiaohu Guo, Wenping Wang, and Alla ShefferIn ACM SIGGRAPH 2026 Conference Papers, Los Angeles, CA, USA, Jul 2026Representing complex geometry as a displacement function defined over a coarse base mesh enables compact storage and accelerated rendering. The core challenge in converting detailed triangle meshes into this representation is computing base meshes that have as few triangles as possible, while also supporting displacement functions that accurately approximate the input. Accurate approximation requires the supported displacement functions to bijectively map the input surface onto the base with low parametric distortion. We observe that this distortion can be measured by evaluating the pointwise Jacobian of the displacement functions. Our new DJM (Displacement Jacobian Metric)-based base-mesh construction method uses the Jacobian of the displacement functions to guide base mesh computation, enabling us to outperform prior approaches in terms of accuracy to size trade-off. We achieve this goal by proposing a variant of the QEM-based simplification scheme that constrains the displacement mapping between the input and the base to be bijective and low distortion (defined as satisfying a lower bound on the mapping Jacobian). When evaluating and encoding the displacement maps, we avoid unreliable ray-mesh intersections by explicitly storing the mapping between the input mesh and the base throughout the construction process, and use this mapping within a robust inverse barycentric displacement solver to obtain dense base-to-mesh correspondences to assist all computations. We demonstrate DJM to outperform alternative schemes in terms of reconstruction accuracy to size trade-off, and demonstrate its robustness and usability for micromesh based rendering and neural encoding.
2025
- TOG
 NESI: Neural Explicit-Shape-Intersection-Based Geometry RepresentationCongyi Zhang, Jinfan Yang, Eric Hedlin, Suzuran Takikawa, Nicholas Vining, Kwang Moo Yi, Wenping Wang, and Alla ShefferACM Trans. Graph., Jul 2025(presented at SIGGRAPH Asia 2025)
NESI: Neural Explicit-Shape-Intersection-Based Geometry RepresentationCongyi Zhang, Jinfan Yang, Eric Hedlin, Suzuran Takikawa, Nicholas Vining, Kwang Moo Yi, Wenping Wang, and Alla ShefferACM Trans. Graph., Jul 2025(presented at SIGGRAPH Asia 2025)Compressed representations of 3D shapes that are compact, accurate, and can be processed efficiently directly in compressed form, are extremely useful for digital media applications. Recent approaches in this space focus on learned implicit or parametric representations. While implicits are well suited for tasks such as in-out queries, they lack natural 2D parameterization, complicating tasks such as texture or normal mapping. Conversely, parametric representations support the latter tasks but are ill-suited for occupancy queries. We propose a novel learned alternative to these approaches, based on intersections of localized explicit, or height-field, surfaces. Since explicits can be trivially expressed both implicitly and parametrically, NESI directly supports a wider range of processing operations than implicit alternatives, including occupancy queries and parametric access. We represent input shapes using a collection of differently oriented height-field bounded half-spaces combined using volumetric Boolean intersections. We first tightly bound each input using a pair of oppositely oriented height-fields, forming a Double Height-Field (DHF) Hull. We refine this hull by intersecting it with additional localized height-fields (HFs) that capture surface regions in its interior. We minimize the number of HFs necessary to accurately capture each input and compactly encode both the DHF hull and the local HFs as neural functions defined over subdomains of (mathbb R^2) . This reduced dimensionality encoding delivers high-quality compact approximations. Given similar parameter count, or storage capacity, NESI significantly reduces approximation error compared to the state-of-the-art, especially at lower parameter counts.
- TOG
 NeuPPS: Neural Piecewise Parametric SurfacesLei Yang, Yongqing Liang, Xin Li, Congyi Zhang, Guying Lin, Cheng Lin, Alla Sheffer, Scott Schaefer, John Keyser, and Wenping WangACM Trans. Graph., Oct 2025(presented at SIGGRAPH Asia 2025)
NeuPPS: Neural Piecewise Parametric SurfacesLei Yang, Yongqing Liang, Xin Li, Congyi Zhang, Guying Lin, Cheng Lin, Alla Sheffer, Scott Schaefer, John Keyser, and Wenping WangACM Trans. Graph., Oct 2025(presented at SIGGRAPH Asia 2025)Piecewise parametric surfaces have long been established as prevalent geometric representations; however, they often require surface refinement or sophisticated quadrangulation to accurately represent complex geometries. Geometric deep learning has shown that neural networks can provide greater representational power than conventional methods. Nevertheless, approaches using a single parametric surface for shape fitting struggle to capture fine-grained geometric details, while multi-patch methods fail to ensure seamless connections between adjacent patches. We present Neural Piecewise Parametric Surfaces (NeuPPS), the first piecewise neural surface representation that allows for coarse patch layouts composed of arbitrary n-sided surface patches to model complex surface geometries with high precision, offering enhanced flexibility compared to traditional parametric surfaces. This new surface representation guarantees, by construction, the continuity between adjacent patches, a property that other neural patch-based approaches cannot ensure. Two novel components are introduced: a learnable feature complex and a continuous mapping function approximated by multi-layer perceptrons (MLPs). We apply the proposed NeuPPS to surface fitting and shape space learning tasks. Extensive experiments demonstrate the advantages of NeuPPS over traditional parametric representations and existing patch-based learning approaches.
- SIGGRAPH Asia 2025
 NeuVAS: Neural Implicit Surfaces for Variational Shape ModelingPengfei Wang, Qiujie Dong, Fangtian Liang, Hao Pan, Lei Yang, Congyi Zhang, Guying Lin, Caiming Zhang, Yuanfeng Zhou, Changhe Tu, and 4 more authorsACM Trans. Graph., Dec 2025
NeuVAS: Neural Implicit Surfaces for Variational Shape ModelingPengfei Wang, Qiujie Dong, Fangtian Liang, Hao Pan, Lei Yang, Congyi Zhang, Guying Lin, Caiming Zhang, Yuanfeng Zhou, Changhe Tu, and 4 more authorsACM Trans. Graph., Dec 2025Neural implicit shape representation has drawn significant attention in recent years due to its smoothness, differentiability, and topological flexibility. However, directly modeling the shape of a neural implicit surface, especially as the zero-level set of a neural signed distance function (SDF), with sparse geometric control is still a challenging task. Sparse input shape control typically includes 3D curve networks or, more generally, 3D curve sketches, which are unstructured and cannot be connected to form a curve network, and therefore more difficult to deal with. While 3D curve networks or curve sketches provide intuitive shape control, their sparsity and varied topology pose challenges in generating high-quality surfaces to meet such curve constraints. In this paper, we propose NeuVAS, a variational approach to shape modeling using neural implicit surfaces constrained under sparse input shape control, including unstructured 3D curve sketches as well as connected 3D curve networks. Specifically, we introduce a smoothness term based on a functional of surface curvatures to minimize shape variation of the zero-level set surface of a neural SDF. We also develop a new technique to faithfully model G^0 sharp feature curves as specified in the input curve sketches. Comprehensive comparisons with the state-of-the-art methods demonstrate the significant advantages of our method.
- TOG
 Patch-Grid: An Efficient and Feature-Preserving Neural Implicit Surface RepresentationGuying Lin*, Lei Yang*, Congyi Zhang, Hao Pan, Yuhan Ping, Guodong Wei, Taku Komura, John Keyser, and Wenping WangACM Trans. Graph., Apr 2025(presented at SIGGRAPH 2025, * equal contribution)
Patch-Grid: An Efficient and Feature-Preserving Neural Implicit Surface RepresentationGuying Lin*, Lei Yang*, Congyi Zhang, Hao Pan, Yuhan Ping, Guodong Wei, Taku Komura, John Keyser, and Wenping WangACM Trans. Graph., Apr 2025(presented at SIGGRAPH 2025, * equal contribution)Neural implicit representations are known to be more compact for depicting 3D shapes than traditional discrete representations. However, the neural representations tend to round sharp corners or edges and struggle to represent surfaces with open boundaries. Moreover, they are slow to train. We present a unified neural implicit representation, called Patch-Grid, that fits to complex shapes efficiently, preserves sharp features, and effectively models surfaces with open boundaries and thin geometric features. Our superior efficiency comes from embedding each surface patch into a local latent volume and decoding it using a shared MLP decoder, which is pretrained on various local surface geometries. With this pretrained decoder fixed, fitting novel shapes and local shape updates can be done efficiently. The faithful preservation of sharp features is enabled by adopting a novel merge grid to perform local constructive solid geometry (CSG) combinations of surface patches in the cells of an adaptive Octree, yielding better robustness than using a global CSG construction as proposed in the literature. Experiments show that our Patch-Grid method faithfully captures shapes with complex sharp features, open boundaries and thin structures, and outperforms existing learning-based methods in both efficiency and quality for surface fitting and local shape updates.
- SIGGRAPH 2025
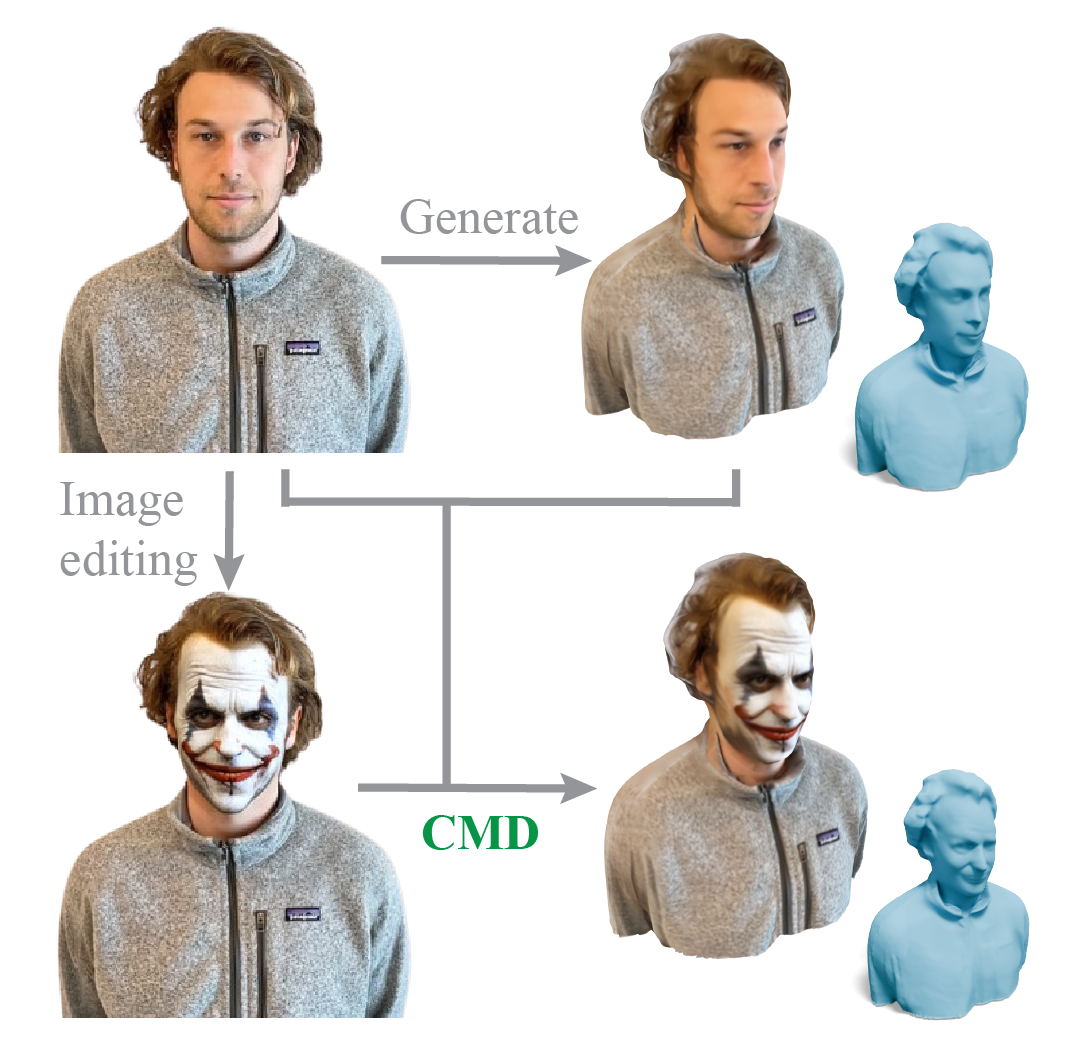 CMD: Controllable Multiview Diffusion for 3D Editing and Progressive GenerationPeng Li, Suizhi Ma, Jialiang Chen, Yuan Liu†, Congyi Zhang, Wei Xue, Wenhan Luo†, Alla Sheffer, Wenping Wang, and Yike GuoIn ACM SIGGRAPH 2025 Conference Papers, Vancouver, BC, CA, Aug 2025(† corresponding author)
CMD: Controllable Multiview Diffusion for 3D Editing and Progressive GenerationPeng Li, Suizhi Ma, Jialiang Chen, Yuan Liu†, Congyi Zhang, Wei Xue, Wenhan Luo†, Alla Sheffer, Wenping Wang, and Yike GuoIn ACM SIGGRAPH 2025 Conference Papers, Vancouver, BC, CA, Aug 2025(† corresponding author)Recently, 3D generation methods have shown their powerful ability to automate 3D model creation. However, most 3D generation methods only rely on an input image or a text prompt to generate a 3D model, which lacks the control of each component of the generated 3D model. Any modifications of the input image lead to an entire regeneration of the 3D models. In this paper, we introduce a new method called CMD that generates a 3D model from an input image while enabling flexible local editing of each component of the 3D model. In CMD, we formulate the 3D generation as a conditional multiview diffusion model, which takes the existing or known parts as conditions and generates the edited or added components. This conditional multiview diffusion model not only allows the generation of 3D models part by part but also enables local editing of 3D models according to the local revision of the input image without changing other 3D parts. Extensive experiments are conducted to demonstrate that CMD decomposes a complex 3D generation task into multiple components, improving the generation quality. Meanwhile, CMD enables efficient and flexible local editing of a 3D model by just editing one rendered image.
- TVCG
 A Potential Field Method for Tooth Motion Planning in Orthodontic TreatmentYumeng Liu, Yuexin Ma, Lei Yang, Congyi Zhang†, Guangshun Wei, Runnan Chen, Min Gu, Jia Pan, Zhengbao Yang, Taku Komura, and 4 more authorsIEEE Transactions on Visualization and Computer Graphics, 2025(† corresponding author)
A Potential Field Method for Tooth Motion Planning in Orthodontic TreatmentYumeng Liu, Yuexin Ma, Lei Yang, Congyi Zhang†, Guangshun Wei, Runnan Chen, Min Gu, Jia Pan, Zhengbao Yang, Taku Komura, and 4 more authorsIEEE Transactions on Visualization and Computer Graphics, 2025(† corresponding author)Invisible orthodontics, commonly known as clear alignment treatment, offers a more comfortable and aesthetically pleasing alternative in orthodontic care, attracting considerable attention in the dental community in recent years. It replaces conventional metal braces with a series of removable, and transparent aligners. Each aligner is crafted to facilitate a gradual adjustment of the teeth, ensuring progressive stages of dental correction. This necessitates the design for teeth motion. Here we present an automatic method and a system for generating collision-free teeth motion planning while avoiding gaps between adjacent teeth, which is unacceptable in clinical practice. To tackle this task, we formulate it as a constrained optimization problem and utilize the interior point method for its solution. We also developed an interactive system that enables dentists to easily visualize and edit the paths. Our method significantly speeds up the clear aligner planning process, creating the desired motion paths for a full set of teeth in under five minutes—a task that typically requires several hours of manual work. Our experiments and user studies confirm the effectiveness of this method in planning teeth movement, showcasing its potential to streamline orthodontic procedures.
2024
- SIGGRAPH 2024
 TexPainter: Generative Mesh Texturing with Multi-view ConsistencyIn ACM SIGGRAPH 2024 Conference Papers, Denver, CO, USA, Jul 2024
TexPainter: Generative Mesh Texturing with Multi-view ConsistencyIn ACM SIGGRAPH 2024 Conference Papers, Denver, CO, USA, Jul 2024The recent success of pre-trained diffusion models unlocks the possibility of the automatic generation of textures for arbitrary 3D meshes in the wild. However, these models are trained in the screen space, while converting them to a multi-view consistent texture image poses a major obstacle to the output quality. In this paper, we propose a novel method to enforce multi-view consistency. Our method is based on the observation that latent space in a pre-trained diffusion model is noised separately for each camera view, making it difficult to achieve multi-view consistency by directly manipulating the latent codes. Based on the celebrated Denoising Diffusion Implicit Models (DDIM) scheme, we propose to use an optimization-based color-fusion to enforce consistency and indirectly modify the latent codes by gradient back-propagation. Our method further relaxes the sequential dependency assumption among the camera views. By evaluating on a series of general 3D models, we find our simple approach improves consistency and overall quality of the generated textures as compared to competing state-of-the-arts.
- TVCG
 Skull-to-Face: Anatomy-Guided 3D Facial Reconstruction and EditingIEEE Transactions on Visualization and Computer Graphics, Nov 2024
Skull-to-Face: Anatomy-Guided 3D Facial Reconstruction and EditingIEEE Transactions on Visualization and Computer Graphics, Nov 2024Deducing the 3D face from a skull is a challenging task in forensic science and archaeology. This paper proposes an end-to-end 3D face reconstruction pipeline and an exploration method that can conveniently create textured, realistic faces that match the given skull. To this end, we propose a tissue-guided face creation and adaptation scheme. With the help of the state-of-the-art text-to-image diffusion model and parametric face model, we first generate an initial reference 3D face, whose biological profile aligns with the given skull. Then, with the help of tissue thickness distribution, we modify these initial faces to match the skull through a latent optimization process. The joint distribution of tissue thickness is learned on a set of skull landmarks using a collection of scanned skull-face pairs. We also develop an efficient face adaptation tool to allow users to interactively adjust tissue thickness either globally or at local regions to explore different plausible faces. Experiments conducted on a real skull-face dataset demonstrated the effectiveness of our proposed pipeline in terms of reconstruction accuracy, diversity, and stability.
- TVCG
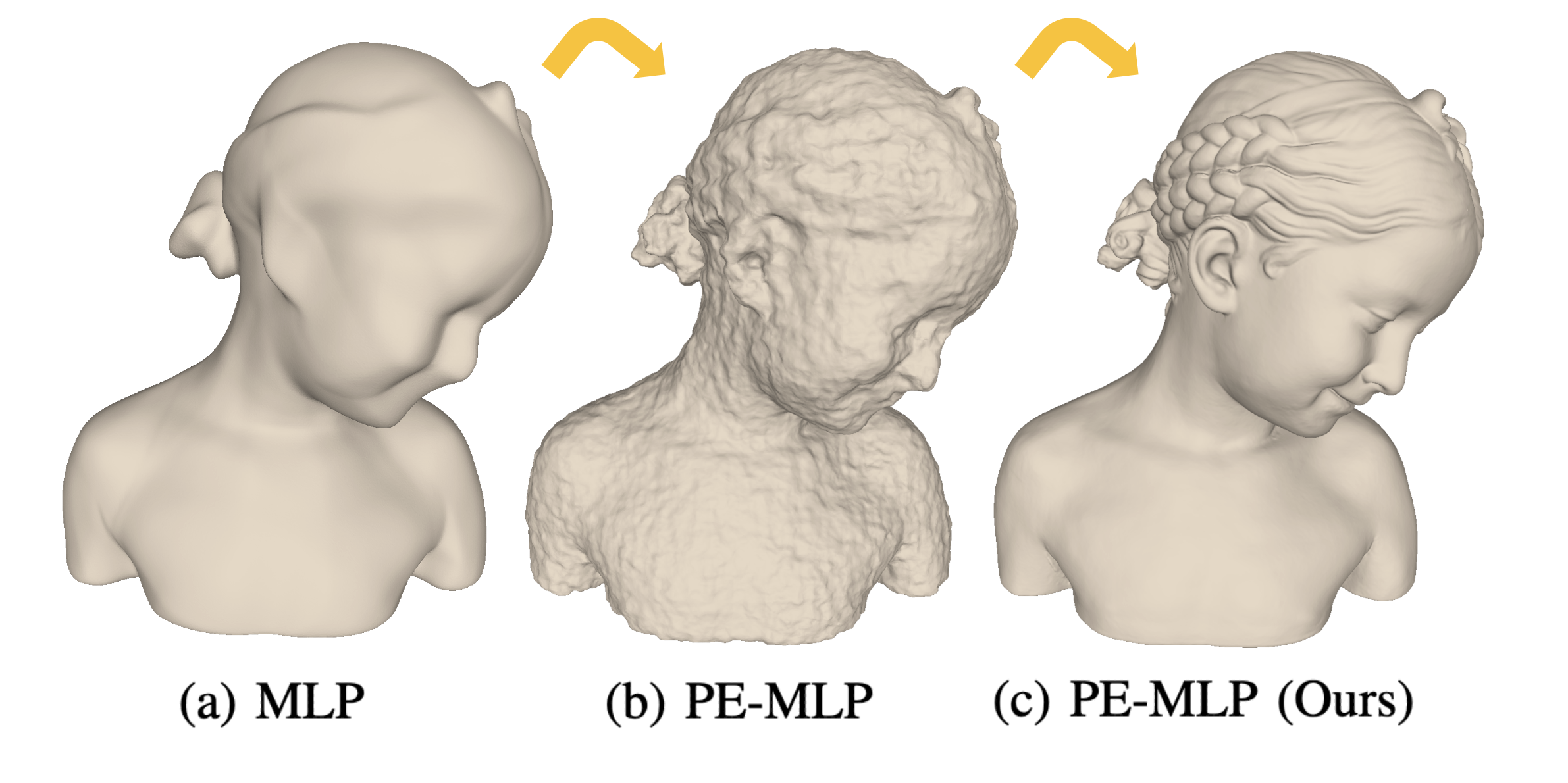 On Optimal Sampling for Learning SDF Using MLPs Equipped with Positional EncodingGuying Lin*, Lei Yang*, Yuan Liu, Congyi Zhang, Junhui Hou, Xiaogang Jin, Taku Komura, John Keyser, and Wenping WangIEEE Transactions on Visualization and Computer Graphics, Dec 2024(* equal contribution)
On Optimal Sampling for Learning SDF Using MLPs Equipped with Positional EncodingGuying Lin*, Lei Yang*, Yuan Liu, Congyi Zhang, Junhui Hou, Xiaogang Jin, Taku Komura, John Keyser, and Wenping WangIEEE Transactions on Visualization and Computer Graphics, Dec 2024(* equal contribution)Neural implicit fields, such as the neural signed distance field (SDF) of a shape, have emerged as a powerful representation for many applications, e.g., encoding a 3D shape and performing collision detection. Typically, implicit fields are encoded by Multi-layer Perceptrons (MLP) with positional encoding (PE) to capture high-frequency geometric details. However, a notable side effect of such PE-equipped MLPs is the noisy artifacts present in the learned implicit fields. While increasing the sampling rate could in general mitigate these artifacts, in this paper we aim to explain this adverse phenomenon through the lens of Fourier analysis. We devise a tool to determine the appropriate sampling rate for learning an accurate neural implicit field without undesirable side effects. Specifically, we propose a simple yet effective method to estimate the intrinsic frequency of a given network with randomized weights based on the Fourier analysis of the network’s responses. It is observed that a PE-equipped MLP has an intrinsic frequency much higher than the highest frequency component in the PE layer. Sampling against this intrinsic frequency following the Nyquist-Sannon sampling theorem allows us to determine an appropriate training sampling rate. We empirically show in the setting of SDF fitting that this recommended sampling rate is sufficient to secure accurate fitting results, while further increasing the sampling rate would not further noticeably reduce the fitting error. Training PE-equipped MLPs simply with our sampling strategy leads to performances superior to the existing methods.
- TVCG
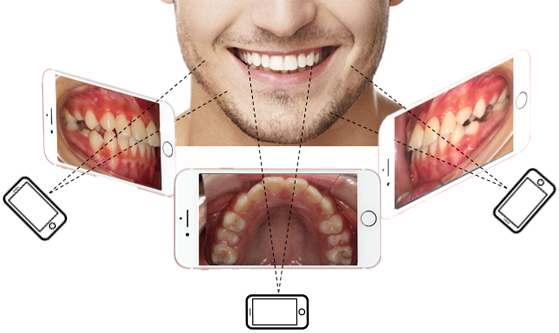 Tooth Motion Monitoring in Orthodontic Treatment by Mobile Device-based Multi-view StereoJiaming Xie, Congyi Zhang, Guangshun Wei, Peng Wang, Guodong Wei, Wenxi Liu, Min Gu, Ping Luo, and Wenping WangIEEE Transactions on Visualization and Computer Graphics, Sep 2024
Tooth Motion Monitoring in Orthodontic Treatment by Mobile Device-based Multi-view StereoJiaming Xie, Congyi Zhang, Guangshun Wei, Peng Wang, Guodong Wei, Wenxi Liu, Min Gu, Ping Luo, and Wenping WangIEEE Transactions on Visualization and Computer Graphics, Sep 2024Nowadays, orthodontics has become an important part of modern personal life to assist one in improving mastication and raising self-esteem. However, the quality of orthodontic treatment still heavily relies on the empirical evaluation of experienced doctors, which lacks quantitative assessment and requires patients to visit clinics frequently for in-person examination. To resolve the aforementioned problem, we propose a novel and practical mobile device-based framework for precisely measuring tooth movement in treatment, so as to simplify and strengthen the traditional tooth monitoring process. To this end, we formulate the tooth movement monitoring task as a multi-view multi-object pose estimation problem via different views that capture multiple texture-less and severely occluded objects (i.e. teeth). Specifically, we exploit a pre-scanned 3D tooth model and a sparse set of multi-view tooth images as inputs for our proposed tooth monitoring framework. After extracting tooth contours and localizing the initial camera pose of each view from the initial configuration, we propose a joint pose estimation scheme to precisely estimate the 3D pose of each individual tooth, so as to infer their relative offsets during treatment. Furthermore, we introduce the metric of Relative Pose Bias to evaluate the individual tooth pose accuracy in a small scale. We demonstrate that our approach is capable of reaching high accuracy and efficiency as practical orthodontic treatment monitoring requires.
2023
- ICCV 2023
 Surface Extraction from Neural Unsigned Distance FieldsCongyi Zhang*, Guying Lin*, Lei Yang, Xin Li, Taku Komura, Scott Schaefer, John Keyser, and Wenping WangIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct 2023(* equal contribution)
Surface Extraction from Neural Unsigned Distance FieldsCongyi Zhang*, Guying Lin*, Lei Yang, Xin Li, Taku Komura, Scott Schaefer, John Keyser, and Wenping WangIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct 2023(* equal contribution)We propose a method, named DualMesh-UDF, to extract a surface from unsigned distance functions (UDFs), encoded by neural networks, or neural UDFs. Neural UDFs are becoming increasingly popular for surface representation because of their versatility in presenting surfaces with arbitrary topologies, as opposed to the signed distance function that is limited to representing a closed surface. However, the applications of neural UDFs are hindered by the notorious difficulty in extracting the target surfaces they represent. Recent methods for surface extraction from a neural UDF suffer from significant geometric errors or topological artifacts due to two main difficulties: (1) A UDF does not exhibit sign changes; and (2) A neural UDF typically has substantial approximation errors. DualMesh-UDF addresses these two difficulties. Specifically, given a neural UDF encoding a target surface S to be recovered, we first estimate the tangent planes of S at a set of sample points close to S. Next, we organize these sample points into local clusters, and for each local cluster, solve a linear least squares problem to determine a final surface point. These surface points are then connected to create the output mesh surface, which approximates the target surface. The robust estimation of the tangent planes of the target surface and the subsequent minimization problem constitute our core strategy, which contributes to the favorable performance of DualMesh-UDF over other competing methods. To efficiently implement this strategy, we employ an adaptive Octree. Within this framework, we estimate the location of a surface point in each of the octree cells identified as containing part of the target surface. Extensive experiments show that our method outperforms existing methods in terms of surface reconstruction quality while maintaining comparable computational efficiency.
- ICCV 2023
 Batch-based Model Registration for Fast 3D Sherd ReconstructionIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct 2023
Batch-based Model Registration for Fast 3D Sherd ReconstructionIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct 20233D reconstruction techniques have widely been used for digital documentation of archaeological fragments. However, efficient digital capture of fragments remains as a challenge. In this work, we aim to develop a portable, high-throughput, and accurate reconstruction system for efficient digitization of fragments excavated in archaeological sites. To realize high-throughput digitization of large numbers of objects, an effective strategy is to perform scanning and reconstruction in batches. However, effective batch-based scanning and reconstruction face two key challenges: 1) how to correlate partial scans of the same object from multiple batch scans, and 2) how to register and reconstruct complete models from partial scans that exhibit only small overlaps. To tackle these two challenges, we develop a new batch-based matching algorithm that pairs the front and back sides of the fragments, and a new Bilateral Boundary ICP algorithm that can register partial scans sharing very narrow overlapping regions. Extensive validation in labs and testing in excavation sites demonstrate that these designs enable efficient batch-based scanning for fragments. We show that such a batch-based scanning and reconstruction pipeline can have immediate applications on digitizing sherds in archaeological excavations.
2022
- SIGGRAPH ASIA 2022
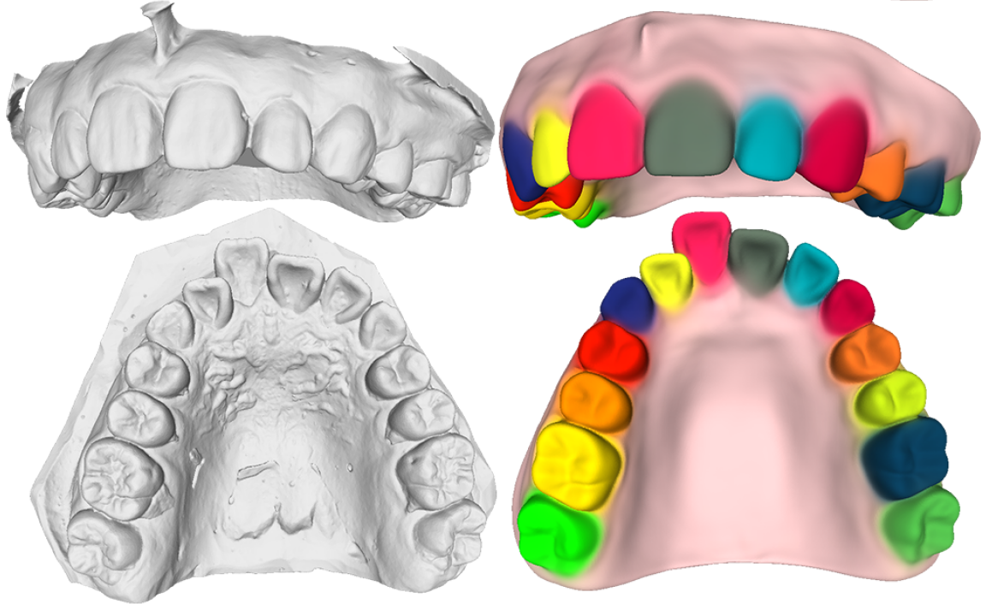 An Implicit Parametric Morphable Dental ModelACM Trans. Graph., Dec 2022
An Implicit Parametric Morphable Dental ModelACM Trans. Graph., Dec 20223D Morphable models of the human body capture variations among subjects and are useful in reconstruction and editing applications. Current dental models use an explicit mesh scene representation and model only the teeth, ignoring the gum. In this work, we present the first parametric 3D morphable dental model for both teeth and gum. Our model uses an implicit scene representation and is learned from rigidly aligned scans. It is based on a component-wise representation for each tooth and the gum, together with a learnable latent code for each of such components. It also learns a template shape thus enabling several applications such as segmentation, interpolation and tooth replacement. Our reconstruction quality is on par with the most advanced global implicit representations while enabling novel applications.
- TVCG
 CreatureShop: Interactive 3D Character Modeling and Texturing from a Single Color DrawingCongyi Zhang, Lei Yang, Nenglun Chen, Nicholas Vining, Alla Sheffer, Francis C.M. Lau, Guoping Wang, and Wenping WangIEEE Transactions on Visualization and Computer Graphics, 2022
CreatureShop: Interactive 3D Character Modeling and Texturing from a Single Color DrawingCongyi Zhang, Lei Yang, Nenglun Chen, Nicholas Vining, Alla Sheffer, Francis C.M. Lau, Guoping Wang, and Wenping WangIEEE Transactions on Visualization and Computer Graphics, 2022Creating 3D shapes from 2D drawings is an important problem with applications in content creation for computer animation and virtual reality. We introduce a new sketch-based system, CreatureShop, that enables amateurs to create high-quality textured 3D character models from 2D drawings with ease and efficiency. CreatureShop takes an input bitmap drawing of a character (such as an animal or other creature), depicted from an arbitrary descriptive pose and viewpoint, and creates a 3D shape with plausible geometric details and textures from a small number of user annotations on the 2D drawing. Our key contributions are a novel oblique view modeling method, a set of systematic approaches for producing plausible textures on the invisible or occluded parts of the 3D character (as viewed from the direction of the input drawing), and a user-friendly interactive system. We validate our system and methods by creating numerous 3D characters from various drawings, and compare our results with related works to show the advantages of our method. We perform a user study to evaluate the usability of our system, which demonstrates that our system is a practical and efficient approach to create fully-textured 3D character models for novice users.
2021
- CHI 2021
 HandPainter - 3D Sketching in VR with Hand-Based Physical ProxyYing Jiang, Congyi Zhang†, Hongbo Fu, Alberto Cannavò, Fabrizio Lamberti, Henry Y K Lau, and Wenping WangIn Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 2021(† corresponding author)
HandPainter - 3D Sketching in VR with Hand-Based Physical ProxyYing Jiang, Congyi Zhang†, Hongbo Fu, Alberto Cannavò, Fabrizio Lamberti, Henry Y K Lau, and Wenping WangIn Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 2021(† corresponding author)3D sketching in virtual reality (VR) enables users to create 3D virtual objects intuitively and immersively. However, previous studies showed that mid-air drawing may lead to inaccurate sketches. To address this issue, we propose to use one hand as a canvas proxy and the index finger of the other hand as a 3D pen. To this end, we first perform a formative study to compare two-handed interaction with tablet-pen interaction for VR sketching. Based on the findings of this study, we design HandPainter, a VR sketching system which focuses on the direct use of two hands for 3D sketching without requesting any tablet, pen, or VR controller. Our implementation is based on a pair of VR gloves, which provide hand tracking and gesture capture. We devise a set of intuitive gestures to control various functionalities required during 3D sketching, such as canvas panning and drawing positioning. We show the effectiveness of HandPainter by presenting a number of sketching results and discussing the outcomes of a user study-based comparison with mid-air drawing and tablet-based sketching tools.
- Anthropometric accuracy of three-dimensional average faces compared to conventional facial measurementsZhiyi Shan, Richard Tai-Chiu Hsung, Congyi Zhang, Juanjuan Ji, Wing Shan Choi, Wenping Wang, Yanqi Yang, Min Gu, and Balvinder S KhambayScientific Reports, 2021
This study aimed to evaluate and compare the accuracy of average faces constructed by different methods. Original three-dimensional facial images of 26 adults in Chinese ethnicity were imported into Di3DView and MorphAnalyser for image processing. Six average faces (Ave_D15, Ave_D24, Ave_MG15, Ave_MG24, Ave_MO15, Ave_MO24) were constructed using “surface-based registration” method with different number of landmarks and template meshes. Topographic analysis was performed, and the accuracy of six average faces was assessed by linear and angular parameters in correspondence with arithmetic means calculated from individual original images. Among the six average faces constructed by the two systems, Ave_MG15 had the highest accuracy in comparison with the conventional method, while Ave_D15 had the least accuracy. Other average faces were comparable regarding the number of discrepant parameters with clinical significance. However, marginal and non-registered areas were the most inaccurate regions using Di3DView. For MorphAnalyser, the type of template mesh had an effect on the accuracy of the final 3D average face, but additional landmarks did not improve the accuracy. This study highlights the importance of validating software packages and determining the degree of accuracy, as well as the variables which may affect the result.
- Homography-guided stereo matching for wide-baseline image interpolationYuan Chang, Congyi Zhang, Yisong Chen, and Guoping WangComputational Visual Media, 2021
Image interpolation has a wide range of applications such as frame rate-up conversion and free viewpoint TV. Despite significant progresses, it remains an open challenge especially for image pairs with large displacements. In this paper, we first propose a novel optimization algorithm for motion estimation, which combines the advantages of both global optimization and a local parametric transformation model. We perform optimization over dynamic label sets, which are modified after each iteration using the prior of piecewise consistency to avoid local minima. Then we apply it to an image interpolation framework including occlusion handling and intermediate image interpolation. We validate the performance of our algorithm experimentally, and show that our approach achieves state-of-the-art performance.
2020
- IEEE VR 2020
 DGaze: CNN-Based Gaze Prediction in Dynamic ScenesZhiming Hu, Sheng Li, Congyi Zhang, Kangrui Yi, Guoping Wang, and Dinesh ManochaIEEE Transactions on Visualization and Computer Graphics, May 2020
DGaze: CNN-Based Gaze Prediction in Dynamic ScenesZhiming Hu, Sheng Li, Congyi Zhang, Kangrui Yi, Guoping Wang, and Dinesh ManochaIEEE Transactions on Visualization and Computer Graphics, May 2020We conduct novel analyses of users’ gaze behaviors in dynamic virtual scenes and, based on our analyses, we present a novel CNN-based model called DGaze for gaze prediction in HMD-based applications. We first collect 43 users’ eye tracking data in 5 dynamic scenes under free-viewing conditions. Next, we perform statistical analysis of our data and observe that dynamic object positions, head rotation velocities, and salient regions are correlated with users’ gaze positions. Based on our analysis, we present a CNN-based model (DGaze) that combines object position sequence, head velocity sequence, and saliency features to predict users’ gaze positions. Our model can be applied to predict not only realtime gaze positions but also gaze positions in the near future and can achieve better performance than prior method. In terms of realtime prediction, DGaze achieves a 22.0% improvement over prior method in dynamic scenes and obtains an improvement of 9.5% in static scenes, based on using the angular distance as the evaluation metric. We also propose a variant of our model called DGaze_ET that can be used to predict future gaze positions with higher precision by combining accurate past gaze data gathered using an eye tracker. We further analyze our CNN architecture and verify the effectiveness of each component in our model. We apply DGaze to gaze-contingent rendering and a game, and also present the evaluation results from a user study.
- SIGGRAPH ASIA 2020
 CPPM: Chi-Squared Progressive Photon MappingZehui Lin, Sheng Li, Xinlu Zeng, Congyi Zhang, Jinzhu Jia, Guoping Wang, and Dinesh ManochaACM Trans. Graph., Nov 2020
CPPM: Chi-Squared Progressive Photon MappingZehui Lin, Sheng Li, Xinlu Zeng, Congyi Zhang, Jinzhu Jia, Guoping Wang, and Dinesh ManochaACM Trans. Graph., Nov 2020We present a novel chi-squared progressive photon mapping algorithm (CPPM) that constructs an estimator by controlling the bandwidth to obtain superior image quality. Our estimator has parametric statistical advantages over prior nonparametric methods. First, we show that when a probability density function of the photon distribution is subject to uniform distribution, the radiance estimation is unbiased under certain assumptions. Next, the local photon distribution is evaluated via a chi-squared test to determine whether the photons follow the hypothesized distribution (uniform distribution) or not. If the statistical test deems that the photons inside the bandwidth are uniformly distributed, bandwidth reduction should be suspended. Finally, we present a pipeline with a bandwidth retention and conditional reduction scheme according to the test results. This pipeline not only accumulates sufficient photons for a reliable chi-squared test, but also guarantees that the estimate converges to the correct solution under our assumptions. We evaluate our method on various benchmarks and observe significant improvement in the running time and rendering quality in terms of mean squared error over prior progressive photon mapping methods.
2019
- SMI 2019
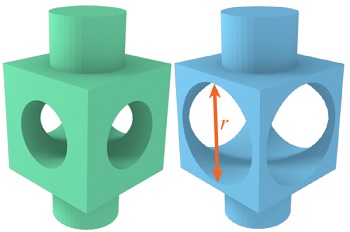 Real-time editing of man-made mesh models under geometric constraintsCongyi Zhang, Lei Yang, Liyou Xu, Guoping Wang, and Wenping WangComputers & Graphics, 2019
Real-time editing of man-made mesh models under geometric constraintsCongyi Zhang, Lei Yang, Liyou Xu, Guoping Wang, and Wenping WangComputers & Graphics, 2019Editing man-made mesh models under multiple geometric constraints is a crucial need for product design to facilitate design exploration and iterative optimization. However, the presence of multiple geometric constraints (e.g. the radius of a cylindrical shape, distance from a point to a plane) as well as the high dimensionality of the discrete mesh representation of man-made models make it difficult to solve this constraint system in real-time. In this paper, we propose an approach based on subspace decomposition to achieve this goal. When a set of variables are edited by the user, the proposed method minimizes the residual of the constraint system in a least square sense to derive a new shape. The resulting shape shall comply with the assigned (extrinsic) constraints while maintaining the original (intrinsic) constraints analyzed from the given mesh model. In particular, we extract a meaningful subspace of the entire solution space based on the user’s edits to reduce the order of the problem, and solve the constraint system globally in real-time. Finally, we project the approximate solution back to the original solution space to obtain the editing result.
- IEEE VR 2019
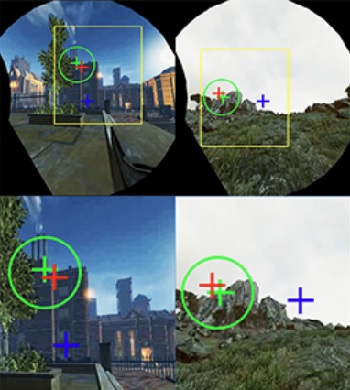 SGaze: A Data-Driven Eye-Head Coordination Model for Realtime Gaze PredictionZhiming Hu, Congyi Zhang, Sheng Li, Guoping Wang, and Dinesh ManochaIEEE Transactions on Visualization and Computer Graphics, May 2019
SGaze: A Data-Driven Eye-Head Coordination Model for Realtime Gaze PredictionZhiming Hu, Congyi Zhang, Sheng Li, Guoping Wang, and Dinesh ManochaIEEE Transactions on Visualization and Computer Graphics, May 2019We present a novel, data-driven eye-head coordination model that can be used for realtime gaze prediction for immersive HMD-based applications without any external hardware or eye tracker. Our model (SGaze) is computed by generating a large dataset that corresponds to different users navigating in virtual worlds with different lighting conditions. We perform statistical analysis on the recorded data and observe a linear correlation between gaze positions and head rotation angular velocities. We also find that there exists a latency between eye movements and head movements. SGaze can work as a software-based realtime gaze predictor and we formulate a time related function between head movement and eye movement and use that for realtime gaze position prediction. We demonstrate the benefits of SGaze for gaze-contingent rendering and evaluate the results with a user study.